

Open-weight large language models for visceral leishmaniasis: Comparative diagnostic accuracy of seven locally-deployed models

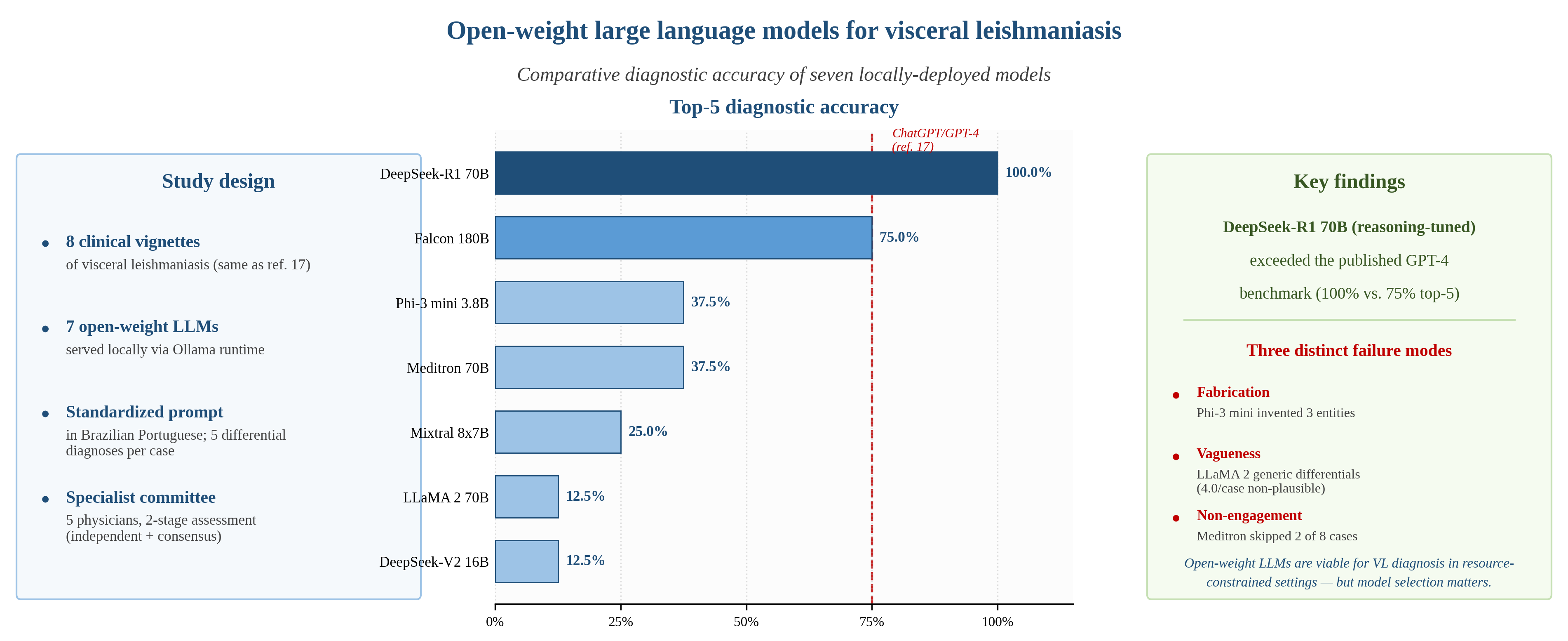
Large language models (LLMs) are increasingly considered as adjuncts for clinical reasoning support, yet most evaluations have focused on cloud-hosted proprietary models. Their open-weight counterparts, which can be deployed locally without transmitting patient data to external servers, remain underexplored—particularly for neglected tropical diseases (NTDs). This exploratory study evaluated the diagnostic performance of seven open-weight LLMs (Falcon 180B, Phi-3 mini 3.8B, LLaMA 2 70B, Meditron 70B, Mixtral 8x7B, DeepSeek-V2 16B, and DeepSeek-R1 70B) for visceral leishmaniasis, using eight clinical vignettes identical in content, prompt, and presentation order to those previously employed to evaluate ChatGPT/GPT-4 by our group. All models were served locally via the Ollama runtime under default inference settings. Top-five and top-one diagnostic accuracy were calculated, and a five-member specialist committee (three infectious-disease physicians and two clinical-diagnosis faculty) classified every generated hypothesis as plausible, non-plausible, or fabricated, after independent assessment and consensus adjudication. Top-five accuracy ranged from 100.0% (DeepSeek-R1 70B; 95% CI: 67.6–100.0) to 12.5% (LLaMA 2 70B and DeepSeek-V2 16B). DeepSeek-R1 70B exceeded the previously published ChatGPT/GPT-4 benchmark of 75.0%; Falcon 180B matched it. Three qualitatively distinct failure modes were identified: fabrication of nosological entities (Phi-3 mini), generic vagueness (LLaMA 2 70B), and non-engagement with the diagnostic task (Meditron 70B). These findings demonstrate that locally-deployed open-weight LLMs can match or exceed proprietary models for VL differential diagnosis, while underscoring the need for expert-validated qualitative assessment beyond binary accuracy metrics. Institution-level evaluation should precede clinical adoption.
- Chappuis F, Sundar S, Hailu A, et al. Visceral leishmaniasis: what are the needs for diagnosis, treatment and control? Nat Rev Microbiol. 2007;5(11):873-882. doi: 10.1038/nrmicro1748
- Lainson R, Rangel EF. Lutzomyia longipalpis and the eco-epidemiology of American visceral leishmaniasis, with particular reference to Brazil: a review. Mem Inst Oswaldo Cruz. 2005;100(8):811-827. doi: 10.1590/s0074-02762005000800001
- Alvar J, Vélez ID, Bern C, et al. Leishmaniasis worldwide and global estimates of its incidence. PLoS ONE. 2012;7(5):e35671. doi: 10.1371/journal.pone.0035671
- de Almeida Soares FM, Rocha TS, Nascimento ER, et al. Human visceral leishmaniasis in Brazil in the past 20 years: an epidemiologic update. Rev Soc Bras Med Trop. 2025;58:e0019-2025. doi: 10.1590/0037-8682-0019-2025
- Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, et al. Attention is all you need. arXiv. Preprint posted online 2017. doi: 10.48550/arXiv.1706.03762
- Thirunavukarasu AJ, Ting DSJ, Elangovan K, Gutierrez L, Tan TF, Ting DSW. Large language models in medicine. Nat Med. 2023;29(8):1930-1940. doi: 10.1038/s41591-023-02448-8
- Maity S, Saikia MJ. Large language models in healthcare and medical applications: a review. Bioengineering. 2025;12(6):631. doi: 10.3390/bioengineering12060631
- Yu KH, Beam AL, Kohane IS. Artificial intelligence in healthcare. Nat Biomed Eng. 2018;2(10):719-731. doi: 10.1038/s41551-018-0305-z
- Egli A. ChatGPT, GPT-4, and other large language models: the next revolution for clinical microbiology? Clin Infect Dis. 2023;77(9):1322-1328. doi: 10.1093/cid/ciad407
- Cheng K, Li Z, He Y, et al. Potential use of artificial intelligence in infectious disease: take ChatGPT as an example. Ann Biomed Eng. 2023;51(6):1130-1135. doi: 10.1007/s10439-023-03203-3
- Hirosawa T, Harada Y, Yokose M, Sakamoto T, Kawamura R, Shimizu T. Diagnostic accuracy of differential-diagnosis lists generated by Generative Pretrained Transformer 3 chatbot for clinical vignettes with common chief complaints: a pilot study. Int J Environ Res Public Health. 2023;20(4):3378. doi: 10.3390/ijerph20043378
- Mizuta K, Hirosawa T, Harada Y, Shimizu T. Can ChatGPT-4 evaluate whether a differential diagnosis list contains the correct diagnosis as accurately as a physician? Diagnosis. 2024;11(3):321-324. doi: 10.1515/dx-2024-0027
- Ueda D, Walston SL, Matsumoto T, Deguchi R, Tatekawa H, Miki Y. Evaluating GPT-4-based ChatGPT’s clinical potential on the NEJM quiz. BMC Digit Health. 2024;2(1):4. doi: 10.1186/s44247-023-00058-5
- Meral G, Ateş S, Günay S, Öztürk A, Kuşdoğan M. Comparative analysis of ChatGPT, Gemini and emergency medicine specialist in ESI triage assessment. Am J Emerg Med. 2024;81:146-150. doi: 10.1016/j.ajem.2024.05.001
- Dinc MT, Kim S, Lee B, Noronha C. Comparative analysis of large language models in clinical diagnosis: performance evaluation across common and complex medical cases. JAMIA Open. 2025;8(3):ooaf055. doi: 10.1093/jamiaopen/ooaf055
- Gaebe K, van der Woerd B. Evaluation of large language models as a diagnostic tool for medical learners and clinicians using advanced prompting techniques. PLoS ONE. 2025;20(8):e0325803. doi: 10.1371/journal.pone.0325803
- Su H, Sun Y, Li R, et al. Large language models in medical diagnostics: scoping review with bibliometric analysis. J Med Internet Res. 2025;27:e72062. doi: 10.2196/72062
- Schwingel PA, Schwingel D, de Aquino SR, et al. An exploratory study on the potential of ChatGPT as an AI-assisted diagnostic tool for visceral leishmaniasis. Artif Intell Health. 2024;1(4):97-106. doi: 10.36922/aih.3930
- da Cruz Pereira RA, Lima RR, Gomes ACA, et al. Exploring the potential of an AI chatbot as a supplementary tool for nutritional prescription at hospital discharge: a preliminary study. Scientifica. 2025;2025:2632410. doi: 10.1155/sci5/2632410
- Soares da Silva ARS, Schwingel D, de Aquino SR, et al. Gender-attributed persona prompts and the diagnostic accuracy of proprietary and open-weight large language models in Chagas disease and visceral leishmaniasis: a paired experimental study. Healthcare. 2026;14(10):1385. doi: 10.3390/healthcare14101385
- Kanter GP, Packel EA. Health care privacy risks of AI chatbots. JAMA. 2023;330(4):311-312. doi: 10.1001/jama.2023.9618
- Cihoric N, Badra EV, Frei AL, et al. Implementing large language models in healthcare while balancing control, collaboration, costs and security. NPJ Digit Med. 2025;8(1):179. doi: 10.1038/s41746-025-01476-7
- Ollama. Get up and running with large language models locally. Accessed January 15, 2025.https://github.com/ ollama/ollama.
- Touvron H, Martin L, Stone K, et al. Llama 2: open foundation and fine-tuned chat models. arXiv. Preprint posted online 2023. doi: 10.48550/arXiv.2307.09288
- Almazrouei E, Alobeidli H, Alshamsi A, et al. The Falcon series of open language models. arXiv. Preprint posted online 2023. doi: 10.48550/arXiv.2311.16867
- Jiang AQ, Sablayrolles A, Roux A, et al. Mixtral of experts. arXiv. Preprint posted online 2024. doi: 10.48550/arXiv.2401.04088
- DeepSeek-AI, Liu A, Feng B, et al. DeepSeek-V2: a strong, economical, and efficient mixture-of-experts language model. arXiv. Preprint posted online 2024. doi: 10.48550/arXiv.2405.04434
- Abdin M, Jacobs SA, Awan AA, et al. Phi-3 technical report: a highly capable language model locally on your phone. arXiv. Preprint posted online 2024. doi: 10.48550/arXiv.2404.14219
- Guo D, Yang D, Zhang H, et al. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature. 2025;645(8081):633-638. doi: 10.1038/s41586-025-09422-z
- Chen Z, Hernández Cano A, Romanou A, et al. MEDITRON- 70B: scaling medical pretraining for large language models. arXiv. Preprint posted online 2023. doi: 10.48550/arXiv.2311.16079
- Sukeda I, Suzuki M, Sakaji H, Kodera S. Development and analysis of medical instruction-tuning for Japanese large language models. Artif Intell Health. 2024;1(2):107-116. doi: 10.36922/aih.2695
- Brown LD, Cai TT, DasGupta A. Interval estimation for a binomial proportion. Stat Sci. 2001;16(2):101-133. doi: 10.1214/ss/1009213286
- Mumtaz U, Ahmed A, Mumtaz S. LLMs-healthcare: current applications and challenges of large language models in various medical specialties. Artif Intell Health. 2024;1(2):16- 28. doi: 10.36922/aih.2558
- Singhal K, Tu T, Gottweis J, et al. Toward expert-level medical question answering with large language models. Nat Med. 2025;31(3):943-950. doi: 10.1038/s41591-024-03423-7
- Sorace L, Hoffmann F, Kottlors J, et al. Benchmarking the diagnostic performance of open source LLMs in 1933 Eurorad case reports. NPJ Digit Med. 2025;8(1):97. doi: 10.1038/s41746-025-01488-3
- Kim H, Hwang H, Lee J, et al. Small language models learn enhanced reasoning skills from medical textbooks. NPJ Digit Med. 2025;8(1):240. doi: 10.1038/s41746-025-01653-8
- Roustan D, Bastardot F. The clinicians’ guide to large language models: a general perspective with a focus on hallucinations. Interact J Med Res. 2025;14:e59823. doi: 10.2196/59823
- Biswas S. ChatGPT and the future of medical writing. Radiology. 2023;307(2):e223312. doi: 10.1148/radiol.223312
- Aquino YS. Making decisions: bias in artificial intelligence and data-driven diagnostic tools. Aust J Gen Pract. 2023;52(7):439-442. doi: 10.31128/AJGP-12-22-6630
- Akhtar ZB. Artificial intelligence within medical diagnostics: a multi-disease perspective. Artif Intell Health. 2025;2(3):44- 62. doi: 10.36922/aih.5173